publications
The list below only includes papers since 2022 and may not be up-to-date. Please refer to Google Scholar for a complete list.
2026
-
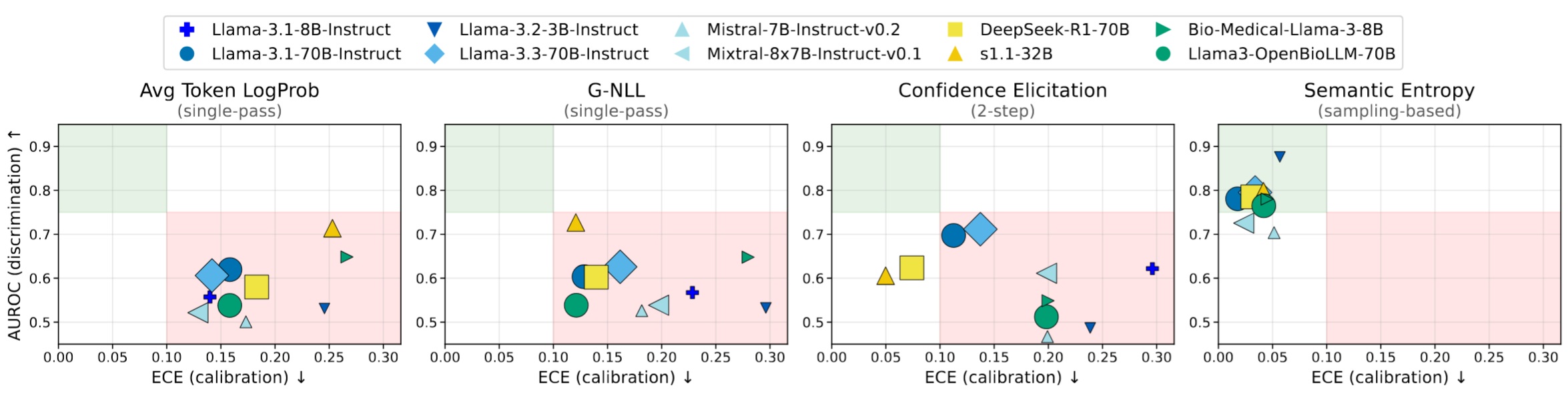 Mind the Gap: Benchmarking LLM Uncertainty and Calibration in Specialty-Aware Clinical QA and Reasoning-Based Behavioural FeaturesAlberto Testoni , and Iacer CalixtoIn 19th Conference of the European Chapter of the Association for Computational Linguistics , 2026
Mind the Gap: Benchmarking LLM Uncertainty and Calibration in Specialty-Aware Clinical QA and Reasoning-Based Behavioural FeaturesAlberto Testoni , and Iacer CalixtoIn 19th Conference of the European Chapter of the Association for Computational Linguistics , 2026@inproceedings{testoni2026mind, title = {Mind the Gap: Benchmarking {LLM} Uncertainty and Calibration in Specialty-Aware Clinical {QA} and Reasoning-Based Behavioural Features}, author = {Testoni, Alberto and Calixto, Iacer}, booktitle = {19th Conference of the European Chapter of the Association for Computational Linguistics}, year = {2026}, url = {https://openreview.net/forum?id=IFXS3EP0dj}, } -
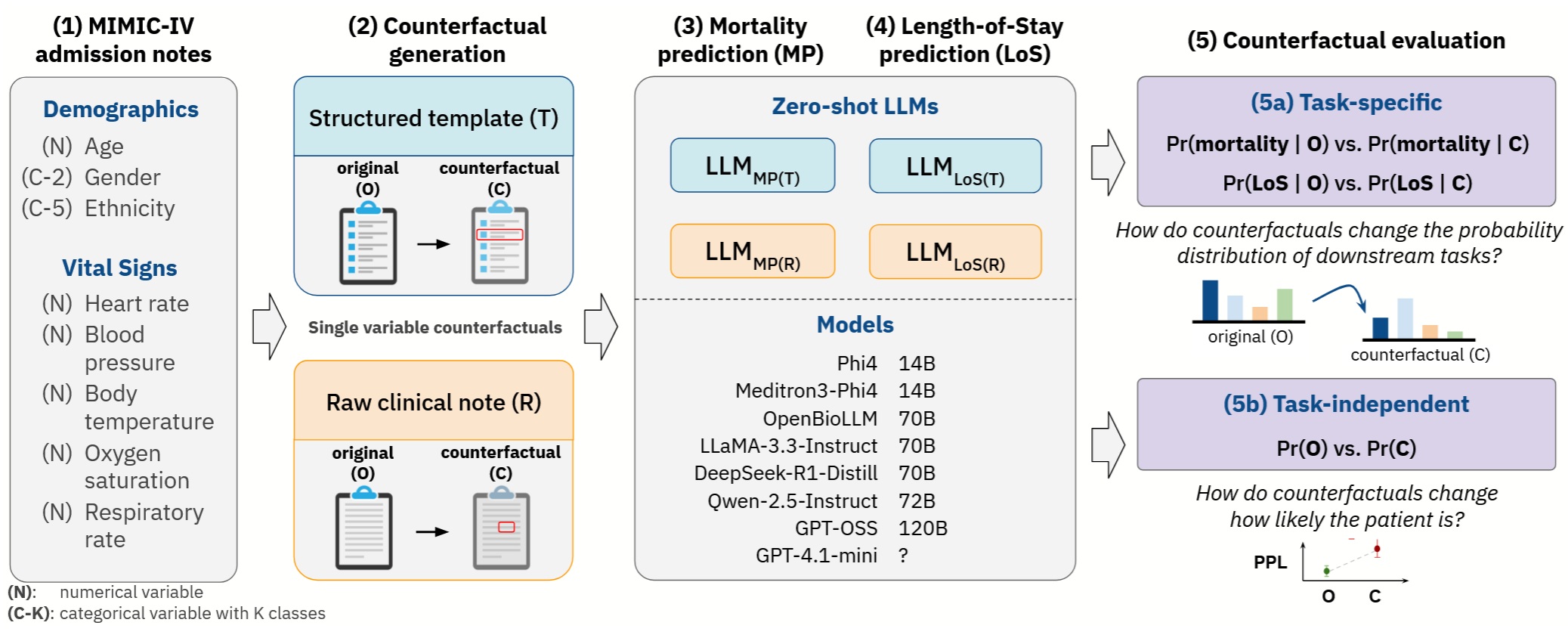 DeVisE: Towards the Behavioral Testing of Medical Large Language ModelsCamila Zurdo Tagliabue , Heloisa Oss Boll , Aykut Erdem , Erkut Erdem , and Iacer CalixtoIn 19th Conference of the European Chapter of the Association for Computational Linguistics , 2026
DeVisE: Towards the Behavioral Testing of Medical Large Language ModelsCamila Zurdo Tagliabue , Heloisa Oss Boll , Aykut Erdem , Erkut Erdem , and Iacer CalixtoIn 19th Conference of the European Chapter of the Association for Computational Linguistics , 2026@inproceedings{tagliabue2026devise, title = {{DeVisE: Towards the Behavioral Testing of Medical Large Language Models}}, author = {Tagliabue, Camila Zurdo and Boll, Heloisa Oss and Erdem, Aykut and Erdem, Erkut and Calixto, Iacer}, booktitle = {19th Conference of the European Chapter of the Association for Computational Linguistics}, year = {2026}, url = {https://openreview.net/forum?id=n68TTKPzbk}, } -
 What Does Infect Mean to Cardio? Investigating the Role of Clinical Specialty Data in Medical LLMsXinlan Yan , Di Wu , Yibin Lei , Christof Monz , and Iacer CalixtoIn 19th Conference of the European Chapter of the Association for Computational Linguistics , 2026
What Does Infect Mean to Cardio? Investigating the Role of Clinical Specialty Data in Medical LLMsXinlan Yan , Di Wu , Yibin Lei , Christof Monz , and Iacer CalixtoIn 19th Conference of the European Chapter of the Association for Computational Linguistics , 2026@inproceedings{yan2026what, title = {What Does Infect Mean to Cardio? Investigating the Role of Clinical Specialty Data in Medical {LLM}s}, author = {Yan, Xinlan and Wu, Di and Lei, Yibin and Monz, Christof and Calixto, Iacer}, booktitle = {19th Conference of the European Chapter of the Association for Computational Linguistics}, year = {2026}, url = {https://openreview.net/forum?id=qkbewQCkWu}, }



2025
-
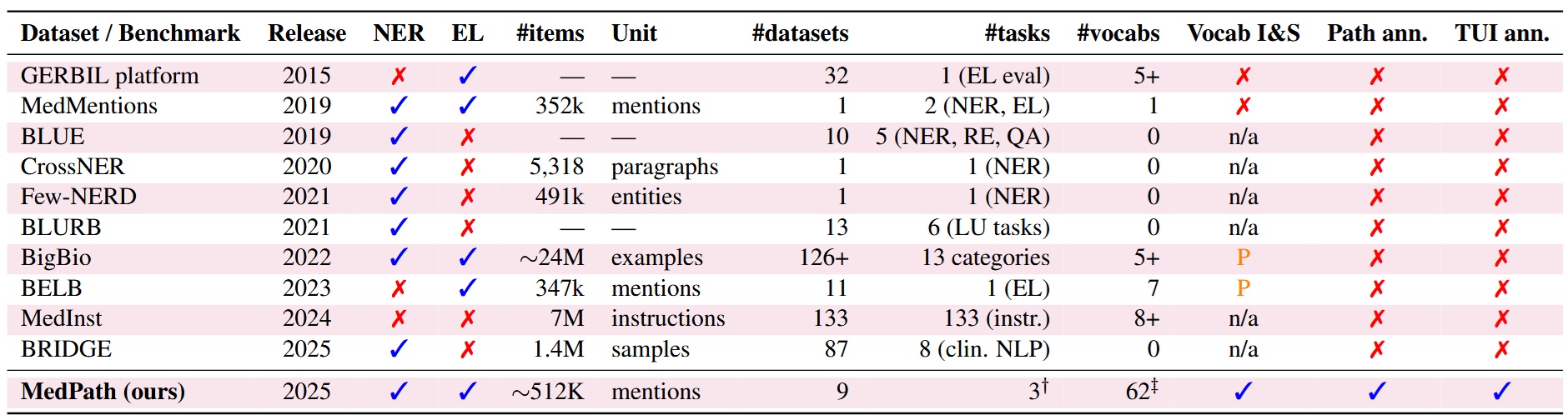 MedPath: Multi-Domain Cross-Vocabulary Hierarchical Paths for Biomedical Entity LinkingNishant Mishra , Wilker Aziz , and Iacer CalixtoIn Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , Dec 2025
MedPath: Multi-Domain Cross-Vocabulary Hierarchical Paths for Biomedical Entity LinkingNishant Mishra , Wilker Aziz , and Iacer CalixtoIn Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , Dec 2025Progress in biomedical Named Entity Recognition (NER) and Entity Linking (EL) is currently hindered by a fragmented data landscape, a lack of resources for building explainable models, and the limitations of semantically-blind evaluation metrics. To address these challenges, we present MedPath, a large-scale and multi-domain biomedical EL dataset that builds upon nine existing expert-annotated EL datasets. In MedPath, all entities are 1) normalized using the latest version of the Unified Medical Language System (UMLS), 2) augmented with mappings to 62 other biomedical vocabularies and, crucially, 3) enriched with full ontological paths—i.e., from general to specific—in up to 11 biomedical vocabularies. MedPath directly enables new research frontiers in biomedical NLP, facilitating training and evaluation of semantic-rich and interpretable EL systems, and the development of the next generation of interoperable and explainable clinical NLP models.
@inproceedings{mishra-etal-2025-medpath, title = {{M}ed{P}ath: Multi-Domain Cross-Vocabulary Hierarchical Paths for Biomedical Entity Linking}, author = {Mishra, Nishant and Aziz, Wilker and Calixto, Iacer}, editor = {Inui, Kentaro and Sakti, Sakriani and Wang, Haofen and Wong, Derek F. and Bhattacharyya, Pushpak and Banerjee, Biplab and Ekbal, Asif and Chakraborty, Tanmoy and Singh, Dhirendra Pratap}, booktitle = {Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics}, month = dec, year = {2025}, address = {Mumbai, India}, publisher = {The Asian Federation of Natural Language Processing and The Association for Computational Linguistics}, url = {https://aclanthology.org/2025.ijcnlp-long.158/}, pages = {2959--2978}, isbn = {979-8-89176-298-5}, } -
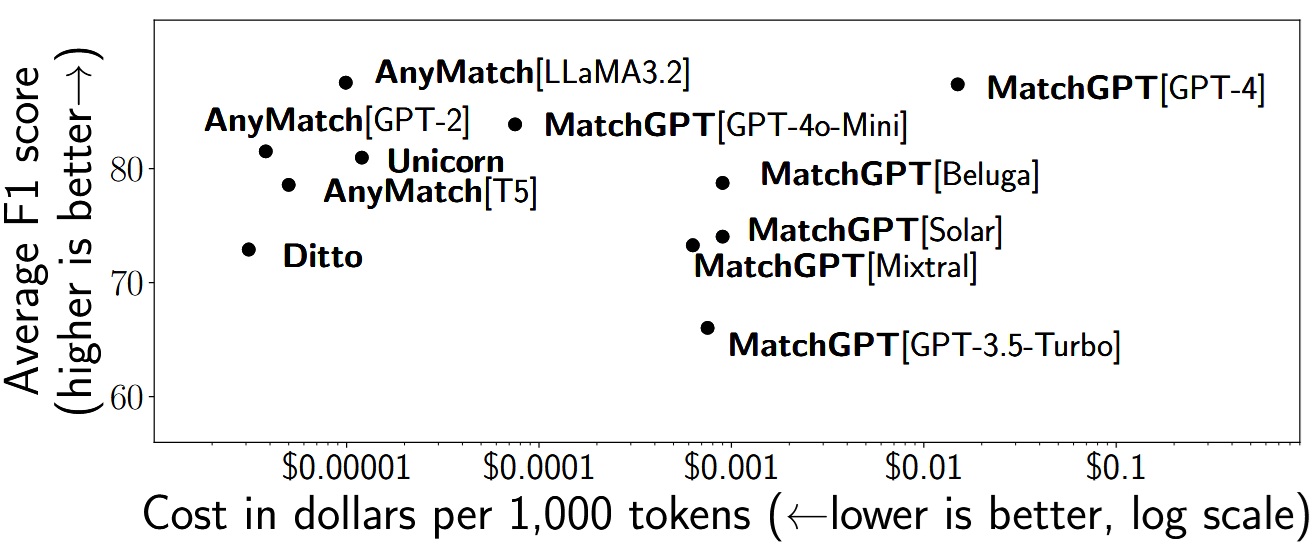 A Deep Dive Into Cross-Dataset Entity Matching with Large and Small Language Models.Zeyu Zhang , Paul Groth , Iacer Calixto , and Sebastian SchelterIn EDBT , Dec 2025
A Deep Dive Into Cross-Dataset Entity Matching with Large and Small Language Models.Zeyu Zhang , Paul Groth , Iacer Calixto , and Sebastian SchelterIn EDBT , Dec 2025@inproceedings{zhang2025deep, title = {A Deep Dive Into Cross-Dataset Entity Matching with Large and Small Language Models.}, author = {Zhang, Zeyu and Groth, Paul and Calixto, Iacer and Schelter, Sebastian}, year = {2025}, pages = {922-934}, publisher = {OpenProceedings.org}, booktitle = {EDBT}, } -
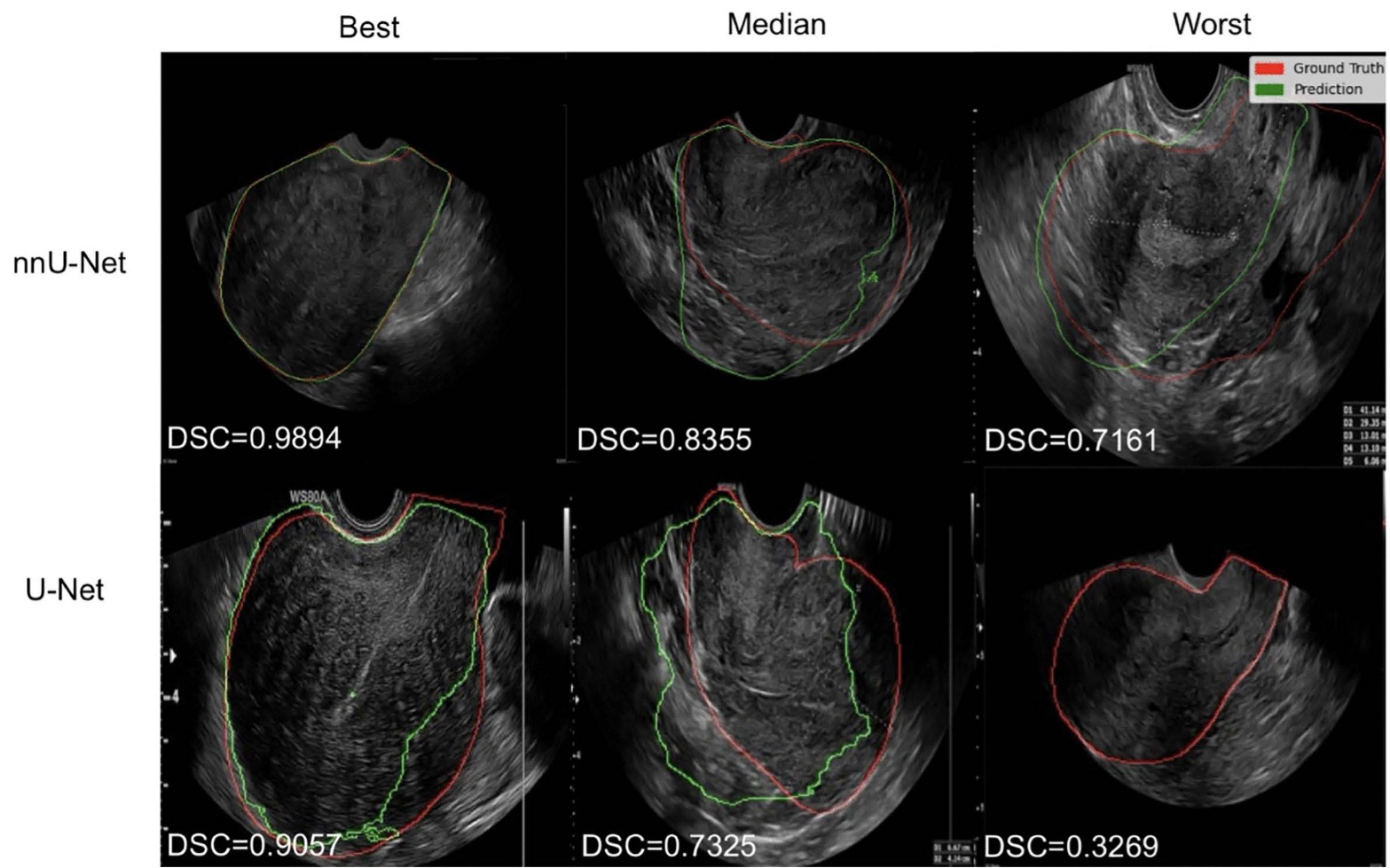 Automatic uterus segmentation in transvaginal ultrasound using U-Net and nnU-NetDilara Tank , Bianca G. S. Schor , Lisa M. Trommelen , Judith A. F. Huirne , Iacer Calixto , and Robert A. LeeuwPLOS ONE, Nov 2025
Automatic uterus segmentation in transvaginal ultrasound using U-Net and nnU-NetDilara Tank , Bianca G. S. Schor , Lisa M. Trommelen , Judith A. F. Huirne , Iacer Calixto , and Robert A. LeeuwPLOS ONE, Nov 2025Purpose Transvaginal ultrasound (TVUS) is pivotal for diagnosing reproductive pathologies in individuals assigned female at birth, often serving as the primary imaging method for gynecologic evaluation. Despite recent advancements in AI-driven segmentation, its application to gynecological ultrasound still needs further attention. Our study aims to bridge this gap by training and evaluating two state-of-the-art deep learning (DL) segmentation models on TVUS data. Materials and methods An experienced gynecological expert manually segmented the uterus in our TVUS dataset of 124 patients with adenomyosis, comprising still images (n = 122), video screenshots (n = 472), and 3D volume screenshots (n = 452). Two popular DL segmentation models, U-Net and nnU-Net, were trained on the entire dataset, and each imaging type was trained separately. Optimization for U-Net included varying batch size, image resolution, pre-processing, and augmentation. Model performance was measured using the Dice score (DSC). Results U-Net and nnU-Net had good mean segmentation performances on the TVUS uterus segmentation dataset (0.75 to 0.97 DSC). We observed that training on specific imaging types (still images, video screenshots, 3D volume screenshots) tended to yield better segmentation performance than training on the complete dataset for both models. Furthermore, nnU-Net outperformed the U-Net across all imaging types. Lastly, we report the best results using the U-Net model with limited pre-processing and augmentations. Conclusions TVUS datasets are well-suited for DL-based segmentation. nnU-Net training was faster and yielded higher segmentation performance; thus, it is recommended over manual U-Net tuning. We also recommend creating TVUS datasets that include only one imaging type and are as clutter-free as possible. The nnU-Net strongly benefited from being trained on 3D volume screenshots in our dataset, likely due to their lack of clutter. Further validation is needed to confirm the robustness of these models on TVUS datasets. Our code is available on https://github.com/dilaratank/UtiSeg.
@article{10.1371/journal.pone.0336237, doi = {10.1371/journal.pone.0336237}, author = {Tank, Dilara and Schor, Bianca G. S. and Trommelen, Lisa M. and Huirne, Judith A. F. and Calixto, Iacer and de Leeuw, Robert A.}, journal = {PLOS ONE}, publisher = {Public Library of Science}, title = {Automatic uterus segmentation in transvaginal ultrasound using U-Net and nnU-Net}, year = {2025}, month = nov, volume = {20}, url = {https://doi.org/10.1371/journal.pone.0336237}, pages = {1-11}, number = {11}, } -
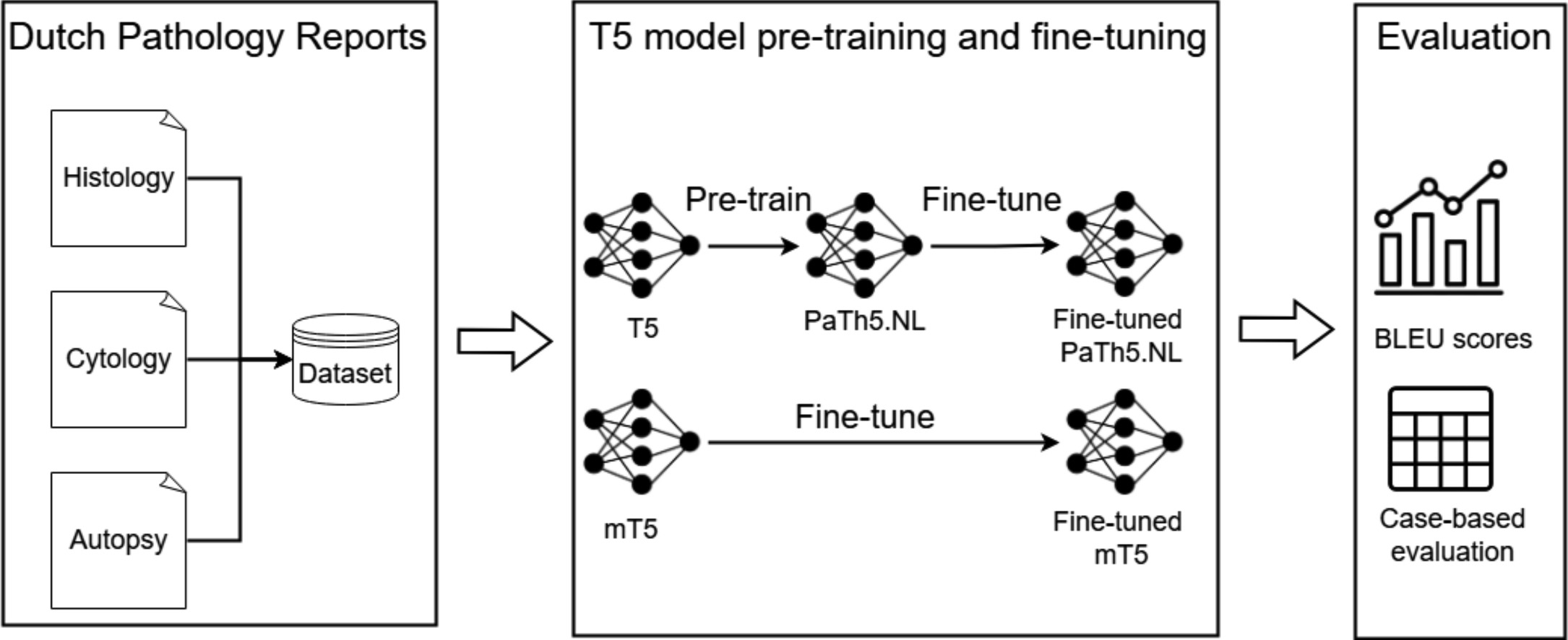 Leveraging sequence-to-sequence models for semantic annotation of Dutch pathology reportsM. Siepel , G.T.N. Burger , Q.J.M. Voorham , R. Cornet , I. Calixto , and I. VaglianoJournal of Pathology Informatics, Nov 2025
Leveraging sequence-to-sequence models for semantic annotation of Dutch pathology reportsM. Siepel , G.T.N. Burger , Q.J.M. Voorham , R. Cornet , I. Calixto , and I. VaglianoJournal of Pathology Informatics, Nov 2025Palga Foundation is responsible for indexing Dutch pathology data across the Netherlands, which relies on annotations of pathology reports. These annotations, derived from the conclusion text, consist of codes from the Palga thesaurus, serving patient care and scientific research. However, manual annotation by pathologists is both labor-intensive and prone to errors. Therefore, in this study, we seek to leverage sequence-to-sequence transformer models, particularly Text-To-Text Transfer Transformer (T5)-based models, to generate these annotations. Additionally, we investigate a constrained decoding (CD) approach that encodes domain knowledge. We compare a standard multilingual T5 model (mT5) with our own T5 model (PaTh5.NL) pre-trained using Palga data with the goal of better aligning the model’s learned representations with the specific structure, terminology, and annotation conventions used in Dutch pathology reports. We fine-tune both pre-trained models using default (DD) and CD and compare both decoding strategies. Performance is assessed using Bilingual Evaluation Understudy (BLEU) scores for quantitative evaluation and case-based evaluations for qualitative assessment, where we use the generated codes to retrieve patients from the Palga database. Quantitative evaluations indicated that our two fine-tuned PaTh5.NL models significantly outperformed the fine-tuned mT5 model, particularly for shorter histology and cytology reports, but performance of all models declined on longer or complex reports. The case-based evaluation revealed that, despite higher BLEU scores, the PaTh5.NL models did not consistently outperform the mT5 model in retrieving relevant patients. This study demonstrates that fine-tuned T5-based models can enhance the annotation process for Dutch pathology reports, though challenges remain regarding complex conclusion texts, especially in histology and autopsy reports. Future research should focus on expanding gold-standard datasets and developing post-processing algorithms to improve annotations’ generalization.
@article{SIEPEL2025100534, title = {Leveraging sequence-to-sequence models for semantic annotation of Dutch pathology reports}, journal = {Journal of Pathology Informatics}, pages = {100534}, year = {2025}, issn = {2153-3539}, doi = {https://doi.org/10.1016/j.jpi.2025.100534}, url = {https://www.sciencedirect.com/science/article/pii/S2153353925001208}, author = {Siepel, M. and Burger, G.T.N. and Voorham, Q.J.M. and Cornet, R. and Calixto, I. and Vagliano, I.}, keywords = {Pathology, Semantic annotation, Deep learning, Transformer, T5, Autoregressive entity retrieval}, } -
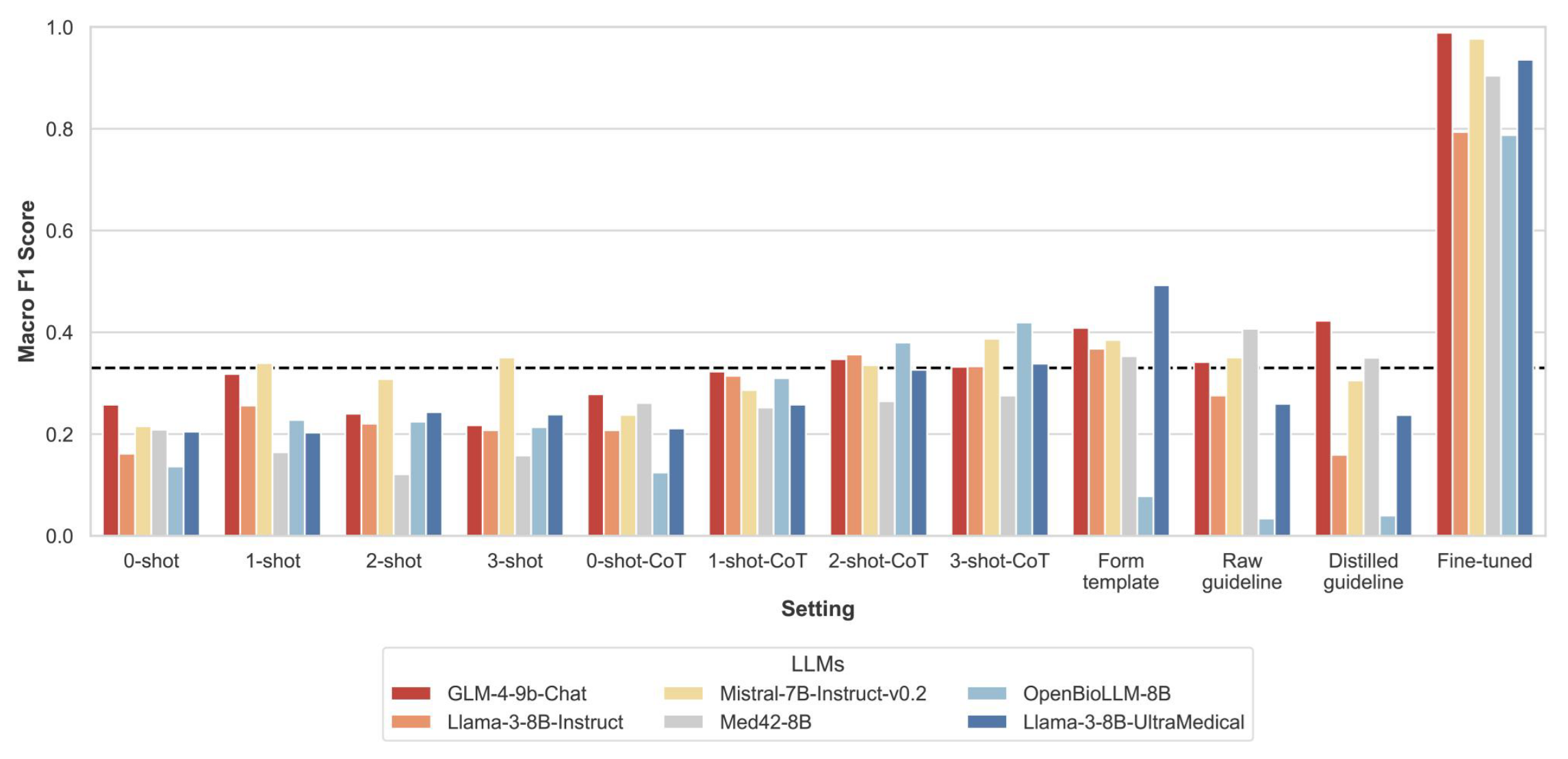 Exploring the potential of large language models for assessing medication adherence to the ESC heart failure guidelinesNoman Dormosh , Machteld Boonstra , Ameen Abu-Hanna , Folkert W Asselbergs , and Iacer CalixtoJAMIA Open, Nov 2025
Exploring the potential of large language models for assessing medication adherence to the ESC heart failure guidelinesNoman Dormosh , Machteld Boonstra , Ameen Abu-Hanna , Folkert W Asselbergs , and Iacer CalixtoJAMIA Open, Nov 2025To evaluate large language models (LLMs) for automating the assessment of clinician adherence to ESC heart failure pharmacotherapy guidelines.We used electronic health records (EHRs) data pertaining to hospitalized heart failure patients. The task was to assess whether discharge medications followed the guidelines. We labeled each record as: (1) all recommended medications are present and target doses achieved; (2) all recommended medications are present, but target doses not achieved; (3) one or more recommended medications are missing. We evaluated three general-domain (GLM-4-9B-chat, Llama3-8B-Instruct, Mistral-7B-Instruct-v0.2) and three medical-specific (Med42-v2-8B, Llama-3-8B-UltraMedical, OpenBioLLM-8B) open-source LLMs under different prompt settings (zero-shot, few-shot and Chain-of-Thought). We fine-tuned the models using synthesized preference data from our EHR data with the Monolithic Preference Optimization without Reference Model (ORPO) method. We performed a learning curve analysis to determine optimal training data size for performance. We assessed LLM performance using the macro F1 score.We included data of 1,141 patients. Adherence to medication and doses was 5.3%. All LLMs scored F1 < 0.40 across most prompt settings (baseline F1 = 0.333). After fine-tuning, four LLMs scored F1 ≥ 0.90; the other two LLMs namely Llama3-8B-Instruct and OpenBioLLM-8B scored F1 = 0.794 and 0.787, respectively. GLM-4-9B-Chat reached peak performance with 40% of the training data, while Mistral-7B-Instruct-v0.2 required 50%. Other models needed more data.Task-specific fine-tuning of LLMs is necessary for optimal performance, and selecting the appropriate LLM for this is important. Without fine-tuning, both general-domain and medical-specific LLMs performed close to random guessing, revealing key limitations in their adaptability to specialized tasks. Medical-specific LLMs showed no clear advantage over general-domain LLMs.Assessing whether clinicians follow heart failure treatment guidelines is essential for ensuring that patients receive the best possible care. However, this process is often labor-intensive and prone to error when done manually. Large language models (LLMs), which are artificial intelligence systems that can understand and generate text, offer a potential solution by automatically analyzing clinical data and assessing adherence to these guidelines.We explored the use of LLMs to evaluate adherence to the European Society of Cardiology (ESC) heart failure guidelines using hospital records from 1,141 patients diagnosed with heart failure. Several general-purpose and medical-specific LLMs were evaluated to determine whether discharge medications met guidelines recommended treatments. No clear advantage was found for medical-specific LLMs over general-purpose LLMs. Without additional training, the models performed poorly, with results close to random guessing. After training LLMs with data tailored to this task, performance improved substantially, with most models achieving over 90 percent accuracy.Our findings highlight both the promise and current limitations of LLMs for specialized healthcare applications. When properly trained, LLMs can automate guideline adherence checks and may also provide useful insights to support improved patient care.
@article{10.1093/jamiaopen/ooaf155, author = {Dormosh, Noman and Boonstra, Machteld and Abu-Hanna, Ameen and Asselbergs, Folkert W and Calixto, Iacer}, title = {Exploring the potential of large language models for assessing medication adherence to the ESC heart failure guidelines}, journal = {JAMIA Open}, volume = {8}, number = {6}, pages = {ooaf155}, year = {2025}, month = nov, issn = {2574-2531}, doi = {10.1093/jamiaopen/ooaf155}, url = {https://doi.org/10.1093/jamiaopen/ooaf155}, eprint = {https://academic.oup.com/jamiaopen/article-pdf/8/6/ooaf155/65346463/ooaf155.pdf}, } -
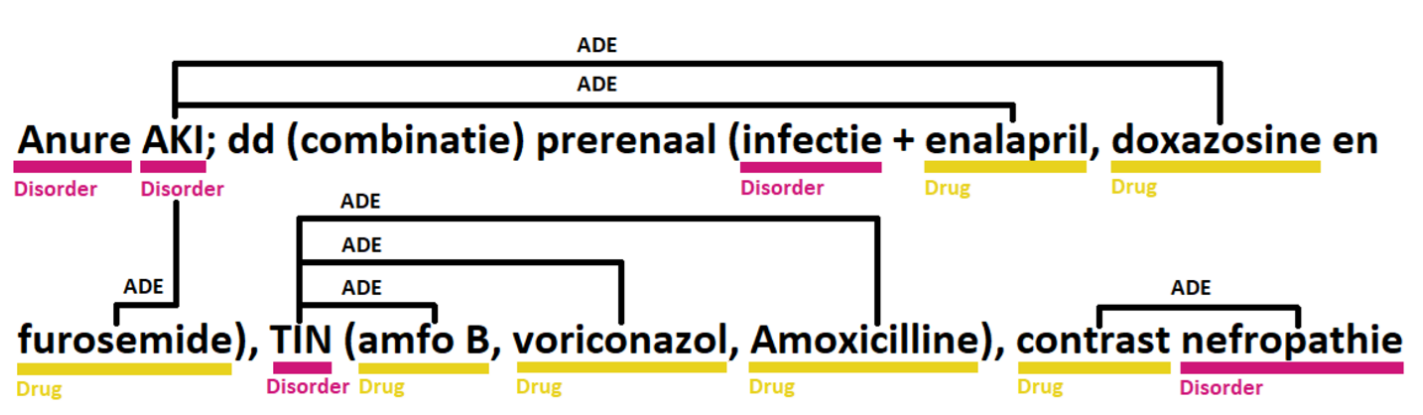 Creation of a gold standard Dutch corpus of clinical notes for adverse drug event detection: the Dutch ADE corpusRachel M. Murphy , Dave A. Dongelmans , Nicolette F. Keizer , Rosa J. Jongeneel , Christiaan H. Koster , Kitty J. Jager , Ameen Abu-Hanna , Iacer Calixto , and 1 more authorLanguage Resources and Evaluation, Sep 2025
Creation of a gold standard Dutch corpus of clinical notes for adverse drug event detection: the Dutch ADE corpusRachel M. Murphy , Dave A. Dongelmans , Nicolette F. Keizer , Rosa J. Jongeneel , Christiaan H. Koster , Kitty J. Jager , Ameen Abu-Hanna , Iacer Calixto , and 1 more authorLanguage Resources and Evaluation, Sep 2025Our objective was to create a gold standard Dutch language annotated corpus of clinical notes with adverse drug event (ADE) mentions, specifically for Intensive Care patients with drug-related acute kidney injury. We used anonymized clinical notes from 102 adult intensive care unit (ICU) patients suspected of acute kidney injury (AKI) and admitted to Amsterdam University Medical Centre, The Netherlands, over a four-year period (November 2015– January 2020). The notes were extracted from the electronic health record (EHR) system and manually reviewed for drug-related causes. Each clinical note contained at least one ADE mention (drug-related AKI). Annotation guidelines were developed over three rounds of annotation based on review of annotations and clarifications during the process. Two clinical expert annotators labelled mentions of drugs and disorders, as well as the relationship between these entities indicating an ADE. The final gold standard corpus was a result of adjudication of the two sets of expert labels. The corpus contains 102 notes with 16,470 labels, consisting of 8,914 Disorder entities, 5,307 Drug entities, 134 Qualitative Concept entities, 1,501 Indication relations, and 614 ADE relations. Annotation reached high agreement for all entities (F1 score 0.7724) with an expected lower agreement for relations (F1 score 0.4327). The Dutch ADE corpus is a real-world data set that can be used to evaluate natural language processing pipelines for ADE detection tasks. Although the corpus was developed for drug-related AKI, 158 additional ADEs were identified. The combination of iterative annotation guideline development and double annotation followed by adjudication produced high quality annotations. Future work will use this gold standard annotated corpus to train and validate NLP models to detect ADEs in Dutch clinical text.
@article{Murphy2025, author = {Murphy, Rachel M. and Dongelmans, Dave A. and de Keizer, Nicolette F. and Jongeneel, Rosa J. and Koster, Christiaan H. and Jager, Kitty J. and Abu-Hanna, Ameen and Calixto, Iacer and Klopotowska, Joanna E.}, title = {Creation of a gold standard Dutch corpus of clinical notes for adverse drug event detection: the Dutch ADE corpus}, journal = {Language Resources and Evaluation}, year = {2025}, month = sep, day = {01}, volume = {59}, number = {3}, pages = {2763-2779}, issn = {1574-0218}, doi = {10.1007/s10579-025-09832-5}, url = {https://doi.org/10.1007/s10579-025-09832-5}, }






2024
-
 Evaluating Linguistic Capabilities of Multimodal LLMs in the Lens of Few-Shot LearningMustafa Dogan , Ilker Kesen , Iacer Calixto , Aykut Erdem , and Erkut ErdemarXiv e-prints, Jul 2024
Evaluating Linguistic Capabilities of Multimodal LLMs in the Lens of Few-Shot LearningMustafa Dogan , Ilker Kesen , Iacer Calixto , Aykut Erdem , and Erkut ErdemarXiv e-prints, Jul 2024@article{2024arXiv240712498D, author = {{Dogan}, Mustafa and {Kesen}, Ilker and {Calixto}, Iacer and {Erdem}, Aykut and {Erdem}, Erkut}, title = {{Evaluating Linguistic Capabilities of Multimodal LLMs in the Lens of Few-Shot Learning}}, journal = {arXiv e-prints}, keywords = {Computer Science - Computation and Language, Computer Science - Computer Vision and Pattern Recognition}, year = {2024}, month = jul, eid = {arXiv:2407.12498}, pages = {arXiv:2407.12498}, doi = {10.48550/arXiv.2407.12498}, archiveprefix = {arXiv}, eprint = {2407.12498}, primaryclass = {cs.CL}, adsurl = {https://ui.adsabs.harvard.edu/abs/2024arXiv240712498D}, adsnote = {Provided by the SAO/NASA Astrophysics Data System}, } -
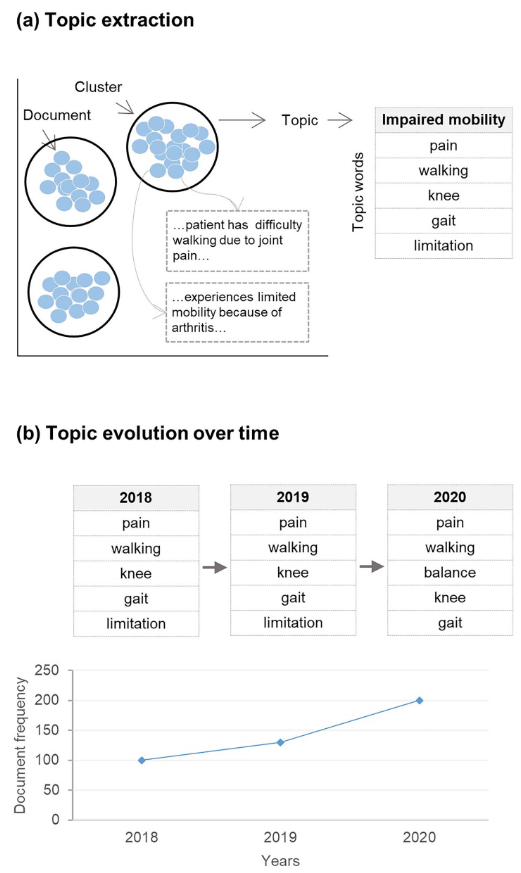 Topic evolution before fall incidents in new fallers through natural language processing of general practitioners’ clinical notesNoman Dormosh , Ameen Abu-Hanna , Iacer Calixto , Martijn C Schut , Martijn W Heymans , and Nathalie VeldeAge and Ageing, Feb 2024
Topic evolution before fall incidents in new fallers through natural language processing of general practitioners’ clinical notesNoman Dormosh , Ameen Abu-Hanna , Iacer Calixto , Martijn C Schut , Martijn W Heymans , and Nathalie VeldeAge and Ageing, Feb 2024Falls involve dynamic risk factors that change over time, but most studies on fall-risk factors are cross-sectional and do not capture this temporal aspect. The longitudinal clinical notes within electronic health records (EHR) provide an opportunity to analyse fall risk factor trajectories through Natural Language Processing techniques, specifically dynamic topic modelling (DTM). This study aims to uncover fall-related topics for new fallers and track their evolving trends leading up to falls.This case–cohort study utilised primary care EHR data covering information on older adults between 2016 and 2019. Cases were individuals who fell in 2019 but had no falls in the preceding three years (2016–18). The control group was randomly sampled individuals, with similar size to the cases group, who did not endure falls during the whole study follow-up period. We applied DTM on the clinical notes collected between 2016 and 2018. We compared the trend lines of the case and control groups using the slopes, which indicate direction and steepness of the change over time.A total of 2,384 fallers (cases) and an equal number of controls were included. We identified 25 topics that showed significant differences in trends between the case and control groups. Topics such as medications, renal care, family caregivers, hospital admission/discharge and referral/streamlining diagnostic pathways exhibited a consistent increase in steepness over time within the cases group before the occurrence of falls.Early recognition of health conditions demanding care is crucial for applying proactive and comprehensive multifactorial assessments that address underlying causes, ultimately reducing falls and fall-related injuries.
@article{10.1093/ageing/afae016, author = {Dormosh, Noman and Abu-Hanna, Ameen and Calixto, Iacer and Schut, Martijn C and Heymans, Martijn W and van der Velde, Nathalie}, title = {{Topic evolution before fall incidents in new fallers through natural language processing of general practitioners’ clinical notes}}, journal = {Age and Ageing}, volume = {53}, number = {2}, pages = {afae016}, year = {2024}, month = feb, issn = {1468-2834}, doi = {10.1093/ageing/afae016}, url = {https://doi.org/10.1093/ageing/afae016}, eprint = {https://academic.oup.com/ageing/article-pdf/53/2/afae016/56669437/afae016.pdf}, } -
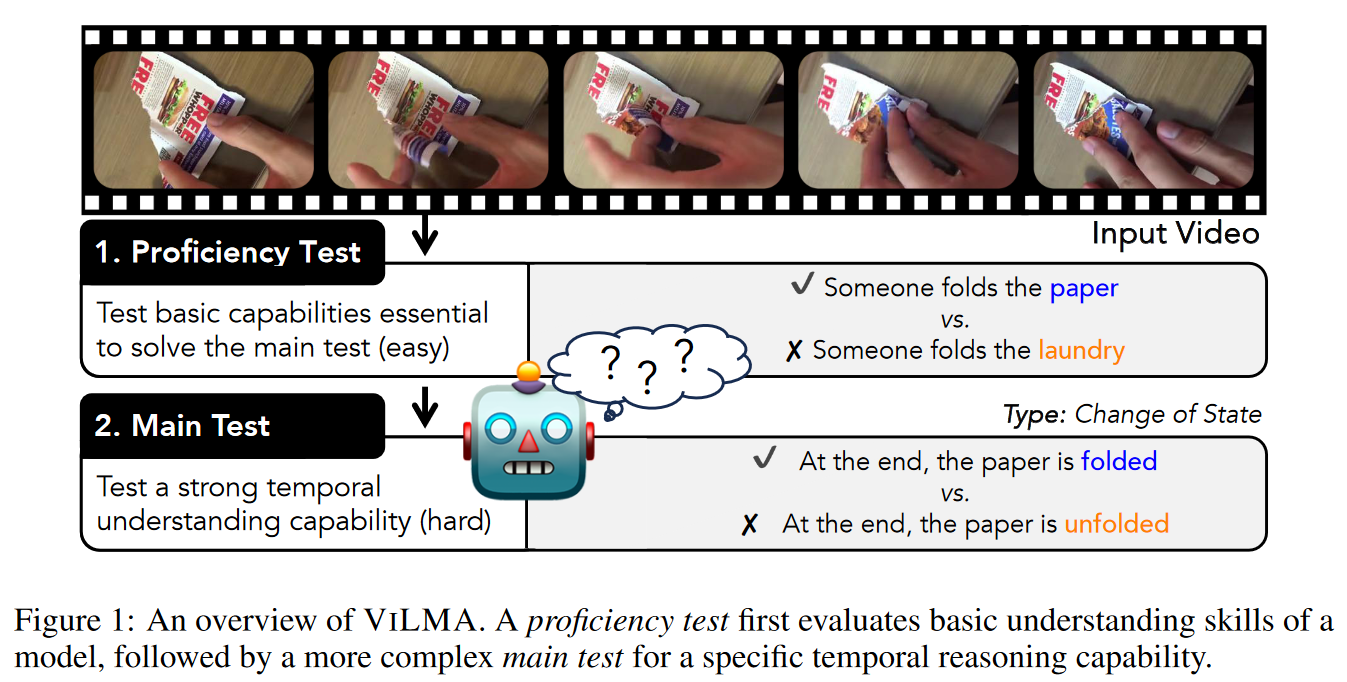 ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language ModelsIlker Kesen , Andrea Pedrotti , Mustafa Dogan , Michele Cafagna , Emre Can Acikgoz , Letitia Parcalabescu , Iacer Calixto , Anette Frank , and 3 more authorsIn The Twelfth International Conference on Learning Representations , Feb 2024
ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language ModelsIlker Kesen , Andrea Pedrotti , Mustafa Dogan , Michele Cafagna , Emre Can Acikgoz , Letitia Parcalabescu , Iacer Calixto , Anette Frank , and 3 more authorsIn The Twelfth International Conference on Learning Representations , Feb 2024@inproceedings{kesen-etal-2024vilma, title = {Vi{LMA}: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models}, author = {Kesen, Ilker and Pedrotti, Andrea and Dogan, Mustafa and Cafagna, Michele and Acikgoz, Emre Can and Parcalabescu, Letitia and Calixto, Iacer and Frank, Anette and Gatt, Albert and Erdem, Aykut and Erkut, Erdem}, booktitle = {The Twelfth International Conference on Learning Representations}, year = {2024}, url = {https://openreview.net/forum?id=liuqDwmbQJ}, }



2023
-
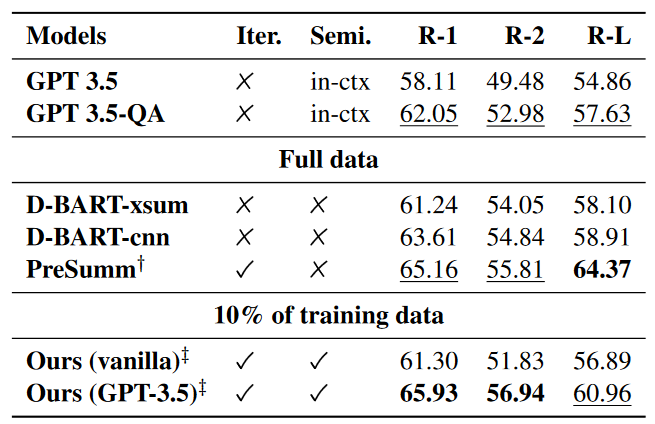 LLM aided semi-supervision for efficient Extractive Dialog SummarizationNishant Mishra , Gaurav Sahu , Iacer Calixto , Ameen Abu-Hanna , and Issam LaradjiIn Findings of the Association for Computational Linguistics: EMNLP 2023 , Dec 2023
LLM aided semi-supervision for efficient Extractive Dialog SummarizationNishant Mishra , Gaurav Sahu , Iacer Calixto , Ameen Abu-Hanna , and Issam LaradjiIn Findings of the Association for Computational Linguistics: EMNLP 2023 , Dec 2023Generating high-quality summaries for chat dialogs often requires large labeled datasets. We propose a method to efficiently use unlabeled data for extractive summarization of customer-agent dialogs. In our method, we frame summarization as a question-answering problem and use state-of-the-art large language models (LLMs) to generate pseudo-labels for a dialog. We then use these pseudo-labels to fine-tune a chat summarization model, effectively transferring knowledge from the large LLM into a smaller specialized model. We demonstrate our method on the TWEETSUMM dataset, and show that using 10% of the original labelled data set we can achieve 65.9/57.0/61.0 ROUGE-1/-2/-L, whereas the current state-of-the-art trained on the entire training data set obtains 65.16/55.81/64.37 ROUGE-1/-2/-L. In other words, in the worst case (i.e., ROUGE-L) we still effectively retain 94.7% of the performance while using only 10% of the data.
@inproceedings{mishra-etal-2023-llm, title = {{LLM} aided semi-supervision for efficient Extractive Dialog Summarization}, author = {Mishra, Nishant and Sahu, Gaurav and Calixto, Iacer and Abu-Hanna, Ameen and Laradji, Issam}, editor = {Bouamor, Houda and Pino, Juan and Bali, Kalika}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2023}, month = dec, year = {2023}, address = {Singapore}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.findings-emnlp.670}, doi = {10.18653/v1/2023.findings-emnlp.670}, pages = {10002--10009}, } - Leveraging Multi-Word Concepts to Predict Acute Kidney Injury in Intensive CareLorenzo Brancato , Iacer Calixto , Ameen Abu-Hanna , and Iacopo VaglianoStud Health Technol Inform, Jun 2023Best paper award
Acute kidney injury (AKI) is an abrupt decrease in kidney function widespread in intensive care. Many AKI prediction models have been proposed, but only few exploit clinical notes and medical terminologies. Previously, we developed and internally validated a model to predict AKI using clinical notes enriched with single-word concepts from medical knowledge graphs. However, an analysis of the impact of using multi-word concepts is lacking. In this study, we compare the use of only the clinical notes as input to prediction to the use of clinical notes retrofitted with both single-word and multi-word concepts. Our results show that 1) retrofitting single-word concepts improved word representations and improved the performance of the prediction model; 2) retrofitting multi-word concepts further improves both results, albeit slightly. Although the improvement with multi-word concepts was small, due to the small number of multi-word concepts that could be annotated, multi-word concepts have proven to be beneficial.
@article{Brancato2023-le, title = {Leveraging {Multi-Word} Concepts to Predict Acute Kidney Injury in Intensive Care}, author = {Brancato, Lorenzo and Calixto, Iacer and Abu-Hanna, Ameen and Vagliano, Iacopo}, journal = {Stud Health Technol Inform}, volume = {305}, pages = {10--13}, month = jun, year = {2023}, address = {Netherlands}, keywords = {Clinical Prediction; Knowledge Graphs; Natural Language Processing}, language = {en}, note = {Best paper award} } -
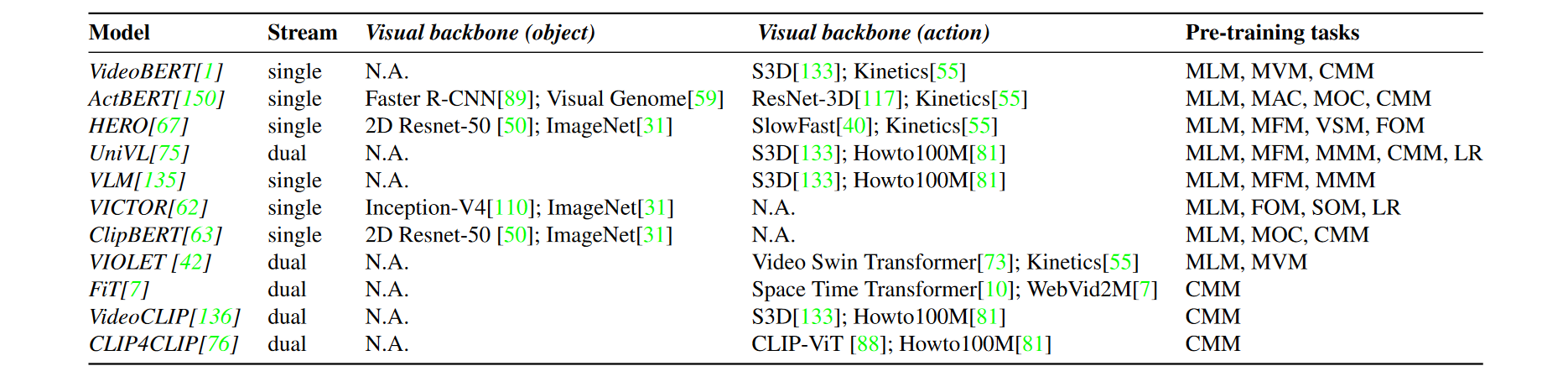 Video-and-Language (VidL) models and their cognitive relevanceAnne Zonneveld , Albert Gatt , and Iacer CalixtoIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops , Oct 2023
Video-and-Language (VidL) models and their cognitive relevanceAnne Zonneveld , Albert Gatt , and Iacer CalixtoIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops , Oct 2023In this paper we give a narrative review of multi-modal video-language (VidL) models. We introduce the current landscape of VidL models and benchmarks, and draw inspiration from neuroscience and cognitive science to propose avenues for future research in VidL models in particular and artificial intelligence (AI) in general. We argue that iterative feedback loops between AI, neuroscience, and cognitive science are essential to spur progress across these disciplines. We motivate why we focus specifically on VidL models and their benchmarks as a promising type of model to bring improvements in AI and categorise current VidL efforts across multiple’cognitive relevance axioms’. Finally, we provide suggestions on how to effectively incorporate this interdisciplinary viewpoint into research on VidL models in particular and AI in general. In doing so, we hope to create awareness of the potential of VidL models to narrow the gap between neuroscience, cognitive science, and AI.
@inproceedings{Zonneveld_2023_ICCV, author = {Zonneveld, Anne and Gatt, Albert and Calixto, Iacer}, title = {Video-and-Language (VidL) models and their cognitive relevance}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops}, month = oct, year = {2023}, pages = {325-338}, } -
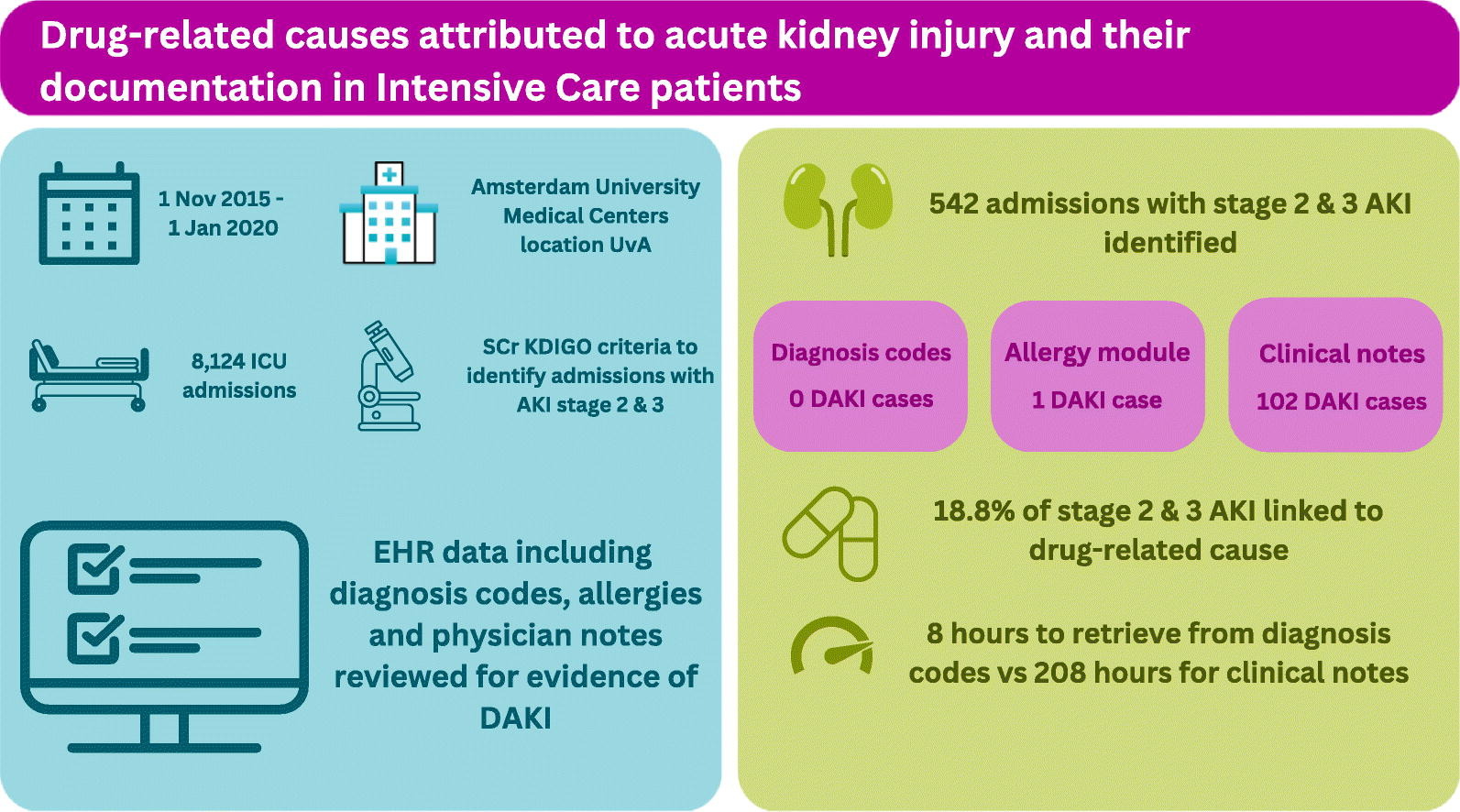 Drug-related causes attributed to acute kidney injury and their documentation in intensive care patientsRachel M. Murphy , Dave A. Dongelmans , Izak Yasrebi-de Kom , Iacer Calixto , Ameen Abu-Hanna , Kitty J. Jager , Nicolette F. de Keizer , and Joanna E. KlopotowskaJournal of Critical Care, Oct 2023
Drug-related causes attributed to acute kidney injury and their documentation in intensive care patientsRachel M. Murphy , Dave A. Dongelmans , Izak Yasrebi-de Kom , Iacer Calixto , Ameen Abu-Hanna , Kitty J. Jager , Nicolette F. de Keizer , and Joanna E. KlopotowskaJournal of Critical Care, Oct 2023Purpose To investigate drug-related causes attributed to acute kidney injury (DAKI) and their documentation in patients admitted to the Intensive Care Unit (ICU). Methods This study was conducted in an academic hospital in the Netherlands by reusing electronic health record (EHR) data of adult ICU admissions between November 2015 to January 2020. First, ICU admissions with acute kidney injury (AKI) stage 2 or 3 were identified. Subsequently, three modes of DAKI documentation in EHR were examined: diagnosis codes (structured data), allergy module (semi-structured data), and clinical notes (unstructured data). Results n total 8124 ICU admissions were included, with 542 (6.7%) ICU admissions experiencing AKI stage 2 or 3. The ICU physicians deemed 102 of these AKI cases (18.8%) to be drug-related. These DAKI cases were all documented in the clinical notes (100%), one in allergy module (1%) and none via diagnosis codes. The clinical notes required the highest time investment to analyze. Conclusions Drug-related causes comprise a substantial part of AKI in the ICU patients. However, current unstructured DAKI documentation practice via clinical notes hampers our ability to gain better insights about DAKI occurrence. Therefore, both automating DAKI identification from the clinical notes and increasing structured DAKI documentation should be encouraged.
@article{MURPHY2023154292, title = {Drug-related causes attributed to acute kidney injury and their documentation in intensive care patients}, journal = {Journal of Critical Care}, volume = {75}, pages = {154292}, year = {2023}, issn = {0883-9441}, doi = {https://doi.org/10.1016/j.jcrc.2023.154292}, url = {https://www.sciencedirect.com/science/article/pii/S0883944123000412}, author = {Murphy, Rachel M. and Dongelmans, Dave A. and Kom, Izak Yasrebi-de and Calixto, Iacer and Abu-Hanna, Ameen and Jager, Kitty J. and {de Keizer}, Nicolette F. and Klopotowska, Joanna E.}, keywords = {Electronic health records, Acute kidney injury, Nephrotoxicity, Phenotype algorithm, Adverse drug event, Automated identification}, } -
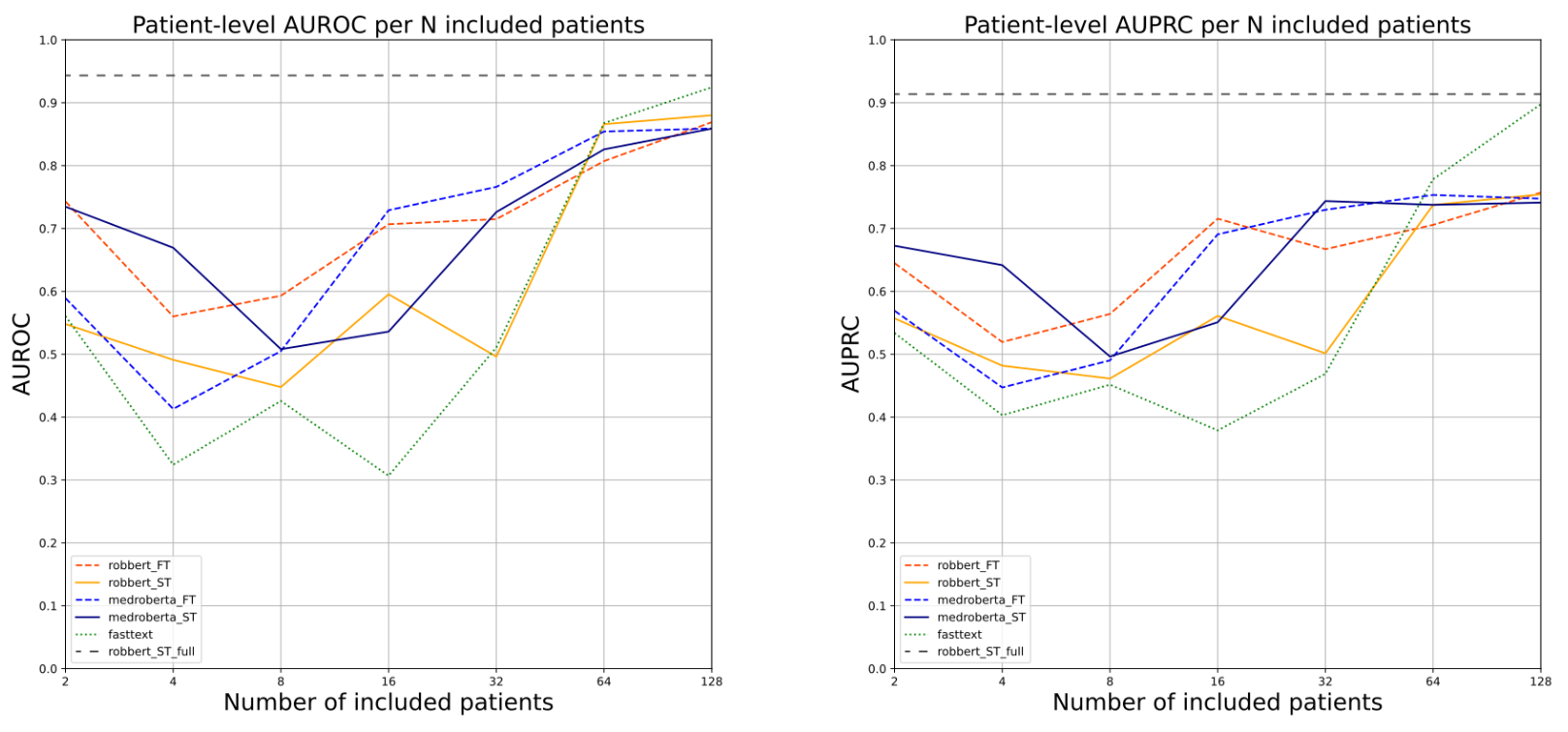 Soft-Prompt Tuning to Predict Lung Cancer Using Primary Care Free-Text Dutch Medical NotesAuke Elfrink , Iacopo Vagliano , Ameen Abu-Hanna , and Iacer CalixtoIn Artificial Intelligence in Medicine , Oct 2023
Soft-Prompt Tuning to Predict Lung Cancer Using Primary Care Free-Text Dutch Medical NotesAuke Elfrink , Iacopo Vagliano , Ameen Abu-Hanna , and Iacer CalixtoIn Artificial Intelligence in Medicine , Oct 2023We examine the use of large Transformer-based pretrained language models (PLMs) for the problem of early prediction of lung cancer using free-text patient medical notes of Dutch primary care physicians. Specifically, we investigate: 1) how soft prompt-tuning compares to standard model fine-tuning; 2) whether simpler static word embedding models (WEMs) can be more robust compared to PLMs in highly imbalanced settings; and 3) how models fare when trained on notes from a small number of patients. All our code is available open source in https://bitbucket.org/aumc-kik/prompt_tuning_cancer_prediction/.
@inproceedings{10.1007/978-3-031-34344-5_23, author = {Elfrink, Auke and Vagliano, Iacopo and Abu-Hanna, Ameen and Calixto, Iacer}, editor = {Juarez, Jose M. and Marcos, Mar and Stiglic, Gregor and Tucker, Allan}, title = {Soft-Prompt Tuning to Predict Lung Cancer Using Primary Care Free-Text Dutch Medical Notes}, booktitle = {Artificial Intelligence in Medicine}, year = {2023}, publisher = {Springer Nature Switzerland}, address = {Cham}, pages = {193--198}, isbn = {978-3-031-34344-5}, } -
 SemEval-2023 Task 1: Visual Word Sense DisambiguationAlessandro Raganato , Iacer Calixto , Asahi Ushio , Jose Camacho-Collados , and Mohammad Taher PilehvarIn Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023) , Jul 2023
SemEval-2023 Task 1: Visual Word Sense DisambiguationAlessandro Raganato , Iacer Calixto , Asahi Ushio , Jose Camacho-Collados , and Mohammad Taher PilehvarIn Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023) , Jul 2023This paper presents the Visual Word Sense Disambiguation (Visual-WSD) task. The objective of Visual-WSD is to identify among a set of ten images the one that corresponds to the intended meaning of a given ambiguous word which is accompanied with minimal context. The task provides datasets for three different languages: English, Italian, and Farsi.We received a total of 96 different submissions. Out of these, 40 systems outperformed a strong zero-shot CLIP-based baseline. Participating systems proposed different zero- and few-shot approaches, often involving generative models and data augmentation. More information can be found on the task’s website: }urlhttps://raganato.github.io/vwsd/.
@inproceedings{raganato-etal-2023-semeval, title = {{S}em{E}val-2023 Task 1: Visual Word Sense Disambiguation}, author = {Raganato, Alessandro and Calixto, Iacer and Ushio, Asahi and Camacho-Collados, Jose and Pilehvar, Mohammad Taher}, booktitle = {Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023)}, month = jul, year = {2023}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.semeval-1.308}, doi = {10.18653/v1/2023.semeval-1.308}, pages = {2227--2234}, } -
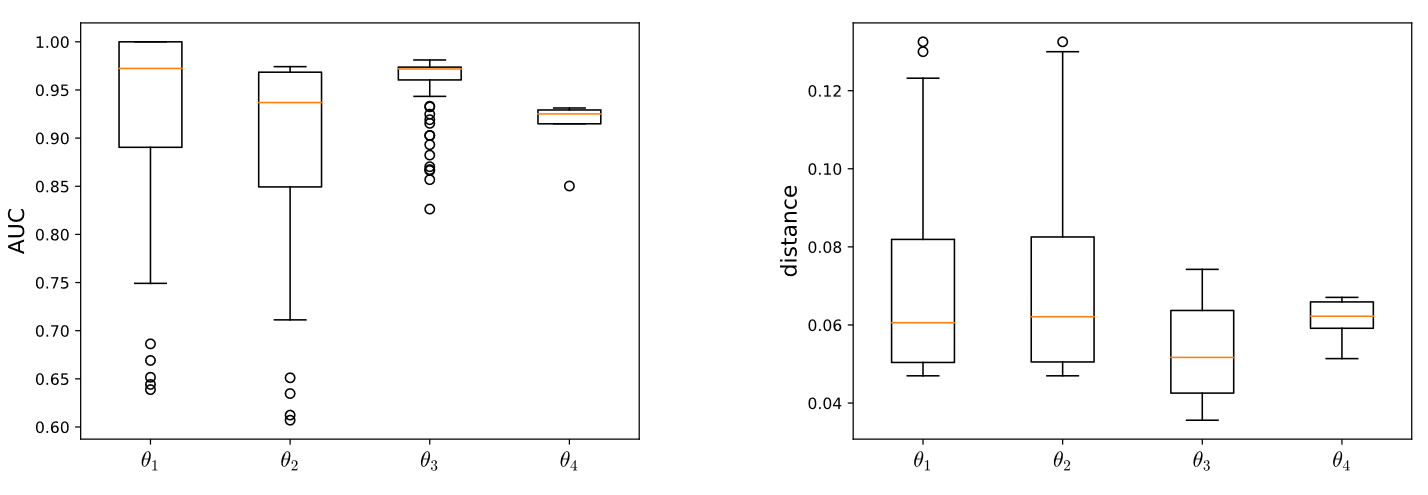 Fixing confirmation bias in feature attribution methods via semantic matchGiovanni Cinà , Daniel Fernandez-Llaneza , Nishant Mishra , Tabea E Röber , Sandro Pezzelle , Iacer Calixto , Rob Goedhart , and Ş İlker BirbilarXiv preprint arXiv:2307.00897, Jul 2023
Fixing confirmation bias in feature attribution methods via semantic matchGiovanni Cinà , Daniel Fernandez-Llaneza , Nishant Mishra , Tabea E Röber , Sandro Pezzelle , Iacer Calixto , Rob Goedhart , and Ş İlker BirbilarXiv preprint arXiv:2307.00897, Jul 2023Feature attribution methods have become a staple method to disentangle the complex behavior of black box models. Despite their success, some scholars have argued that such methods suffer from a serious flaw: they do not allow a reliable interpretation in terms of human concepts. Simply put, visualizing an array of feature contributions is not enough for humans to conclude something about a model’s internal representations, and confirmation bias can trick users into false beliefs about model behavior. We argue that a structured approach is required to test whether our hypotheses on the model are confirmed by the feature attributions. This is what we call the "semantic match" between human concepts and (sub-symbolic) explanations. Building on the conceptual framework put forward in Cinà et al. [2023], we propose a structured approach to evaluate semantic match in practice. We showcase the procedure in a suite of experiments spanning tabular and image data, and show how the assessment of semantic match can give insight into both desirable (e.g., focusing on an object relevant for prediction) and undesirable model behaviors (e.g., focusing on a spurious correlation). We couple our experimental results with an analysis on the metrics to measure semantic match, and argue that this approach constitutes the first step towards resolving the issue of confirmation bias in XAI.
@article{cina2023fixing, title = {Fixing confirmation bias in feature attribution methods via semantic match}, author = {Cin{\`a}, Giovanni and Fernandez-Llaneza, Daniel and Mishra, Nishant and R{\"o}ber, Tabea E and Pezzelle, Sandro and Calixto, Iacer and Goedhart, Rob and Birbil, {\c{S}} {\.I}lker}, journal = {arXiv preprint arXiv:2307.00897}, year = {2023}, }






2022
-
 Multi3Generation: Multitask, Multilingual, Multimodal Language GenerationAnabela Barreiro , José GC Souza , Albert Gatt , Mehul Bhatt , Elena Lloret , Aykut Erdem , Dimitra Gkatzia , Helena Moniz , and 7 more authorsIn Proceedings of the 23rd Annual Conference of the European Association for Machine Translation , Jun 2022
Multi3Generation: Multitask, Multilingual, Multimodal Language GenerationAnabela Barreiro , José GC Souza , Albert Gatt , Mehul Bhatt , Elena Lloret , Aykut Erdem , Dimitra Gkatzia , Helena Moniz , and 7 more authorsIn Proceedings of the 23rd Annual Conference of the European Association for Machine Translation , Jun 2022This paper presents the Multitask, Multilingual, Multimodal Language Generation COST Action – Multi3Generation (CA18231), an interdisciplinary network of research groups working on different aspects of language generation. This “meta-paper” will serve as reference for citations of the Action in future publications. It presents the objectives, challenges and a the links for the achieved outcomes.
@inproceedings{barreiro-etal-2022-multi3generation, title = {{M}ulti3{G}eneration: Multitask, Multilingual, Multimodal Language Generation}, author = {Barreiro, Anabela and de Souza, Jos{\'e} GC and Gatt, Albert and Bhatt, Mehul and Lloret, Elena and Erdem, Aykut and Gkatzia, Dimitra and Moniz, Helena and Russo, Irene and Kepler, Fabio and Calixto, Iacer and Paprzycki, Marcin and Portet, Fran{\c{c}}ois and Augenstein, Isabelle and Alhasani, Mirela}, booktitle = {Proceedings of the 23rd Annual Conference of the European Association for Machine Translation}, month = jun, year = {2022}, address = {Ghent, Belgium}, publisher = {European Association for Machine Translation}, url = {https://aclanthology.org/2022.eamt-1.63}, pages = {347--348}, } -
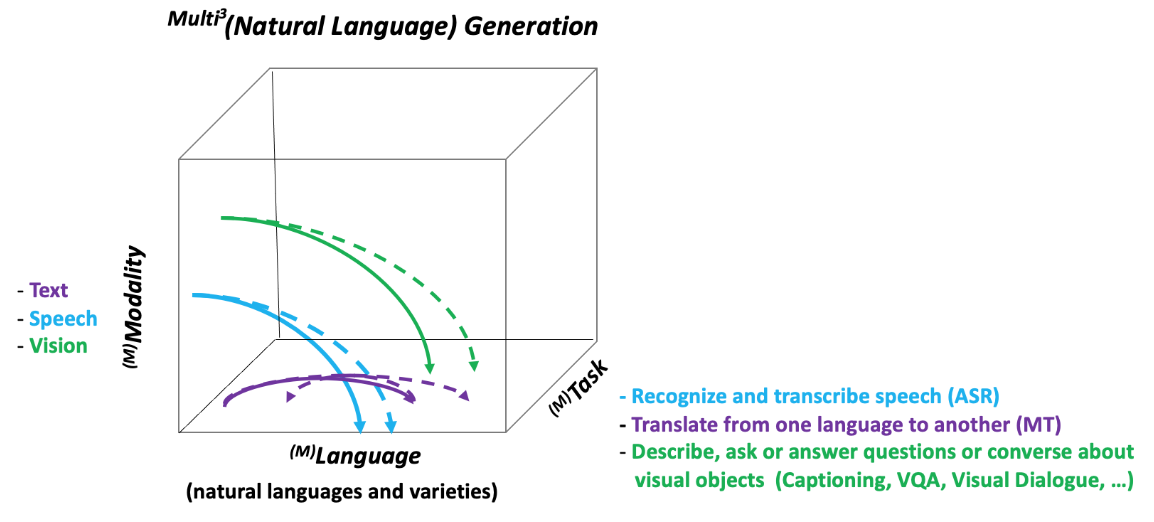 Neural Natural Language Generation: A Survey on Multilinguality, Multimodality, Controllability and LearningErkut Erdem , Menekse Kuyu , Semih Yagcioglu , Anette Frank , Letitia Parcalabescu , Barbara Plank , Andrii Babii , Oleksii Turuta , and 10 more authorsJ. Artif. Int. Res., May 2022
Neural Natural Language Generation: A Survey on Multilinguality, Multimodality, Controllability and LearningErkut Erdem , Menekse Kuyu , Semih Yagcioglu , Anette Frank , Letitia Parcalabescu , Barbara Plank , Andrii Babii , Oleksii Turuta , and 10 more authorsJ. Artif. Int. Res., May 2022Developing artificial learning systems that can understand and generate natural language has been one of the long-standing goals of artificial intelligence. Recent decades have witnessed an impressive progress on both of these problems, giving rise to a new family of approaches. Especially, the advances in deep learning over the past couple of years have led to neural approaches to natural language generation (NLG). These methods combine generative language learning techniques with neural-networks based frameworks. With a wide range of applications in natural language processing, neural NLG (NNLG) is a new and fast growing field of research. In this state-of-the-art report, we investigate the recent developments and applications of NNLG in its full extent from a multidimensional view, covering critical perspectives such as multimodality, multilinguality, controllability and learning strategies. We summarize the fundamental building blocks of NNLG approaches from these aspects and provide detailed reviews of commonly used preprocessing steps and basic neural architectures. This report also focuses on the seminal applications of these NNLG models such as machine translation, description generation, automatic speech recognition, abstractive summarization, text simplification, question answering and generation, and dialogue generation. Finally, we conclude with a thorough discussion of the described frameworks by pointing out some open research directions.
@article{10.1613/jair.1.12918, author = {Erdem, Erkut and Kuyu, Menekse and Yagcioglu, Semih and Frank, Anette and Parcalabescu, Letitia and Plank, Barbara and Babii, Andrii and Turuta, Oleksii and Erdem, Aykut and Calixto, Iacer and Lloret, Elena and Apostol, Elena-Simona and Truic\u{a}, Ciprian-Octavian and \v{S}andrih, Branislava and Martin\v{c}i\'{c}-Ip\v{s}i\'{c}, Sanda and Berend, G\'{a}bor and Gatt, Albert and Korvel, Gr\u{a}zina}, title = {Neural Natural Language Generation: A Survey on Multilinguality, Multimodality, Controllability and Learning}, year = {2022}, issue_date = {May 2022}, publisher = {AI Access Foundation}, address = {El Segundo, CA, USA}, volume = {73}, issn = {1076-9757}, url = {https://doi.org/10.1613/jair.1.12918}, doi = {10.1613/jair.1.12918}, journal = {J. Artif. Int. Res.}, month = may, numpages = {77}, alt_metric = {true}, dimensions = {true}, keywords = {natural language, neural networks} } -
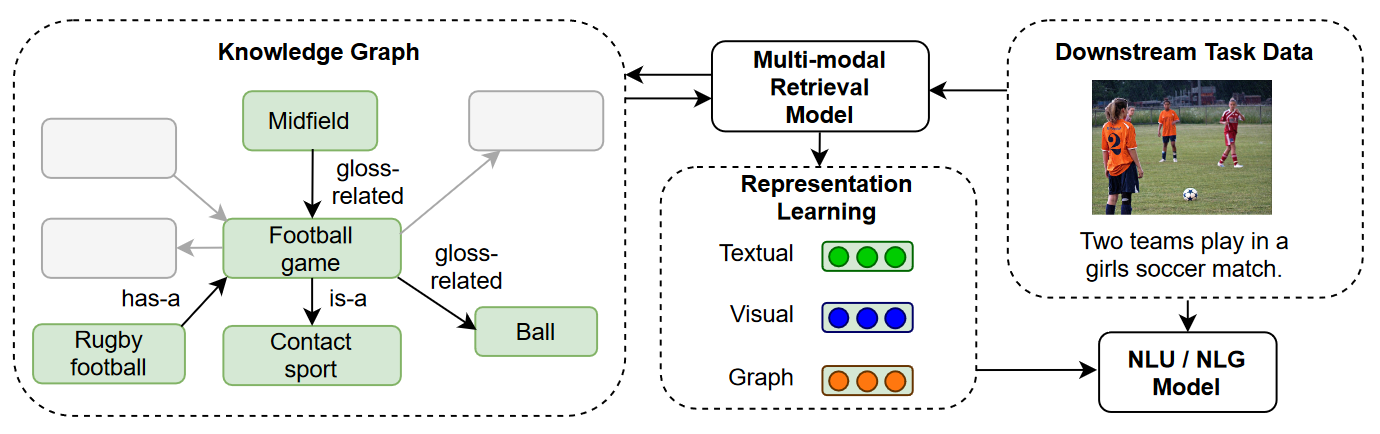 Endowing language models with multimodal knowledge graph representationsNingyuan Huang , Yash R Deshpande , Yibo Liu , Houda Alberts , Kyunghyun Cho , Clara Vania , and Iacer CalixtoarXiv preprint arXiv:2206.13163, May 2022
Endowing language models with multimodal knowledge graph representationsNingyuan Huang , Yash R Deshpande , Yibo Liu , Houda Alberts , Kyunghyun Cho , Clara Vania , and Iacer CalixtoarXiv preprint arXiv:2206.13163, May 2022We propose a method to make natural language understanding models more parameter efficient by storing knowledge in an external knowledge graph (KG) and retrieving from this KG using a dense index. Given (possibly multilingual) downstream task data, e.g., sentences in German, we retrieve entities from the KG and use their multimodal representations to improve downstream task performance. We use the recently released VisualSem KG as our external knowledge repository, which covers a subset of Wikipedia and WordNet entities, and compare a mix of tuple-based and graph-based algorithms to learn entity and relation representations that are grounded on the KG multimodal information. We demonstrate the usefulness of the learned entity representations on two downstream tasks, and show improved performance on the multilingual named entity recognition task by 0.3%–0.7% F1, while we achieve up to 2.5% improvement in accuracy on the visual sense disambiguation task. All our code and data are available in: \urlthis https URL.
@article{huang2022endowing, title = {Endowing language models with multimodal knowledge graph representations}, author = {Huang, Ningyuan and Deshpande, Yash R and Liu, Yibo and Alberts, Houda and Cho, Kyunghyun and Vania, Clara and Calixto, Iacer}, journal = {arXiv preprint arXiv:2206.13163}, year = {2022}, } -
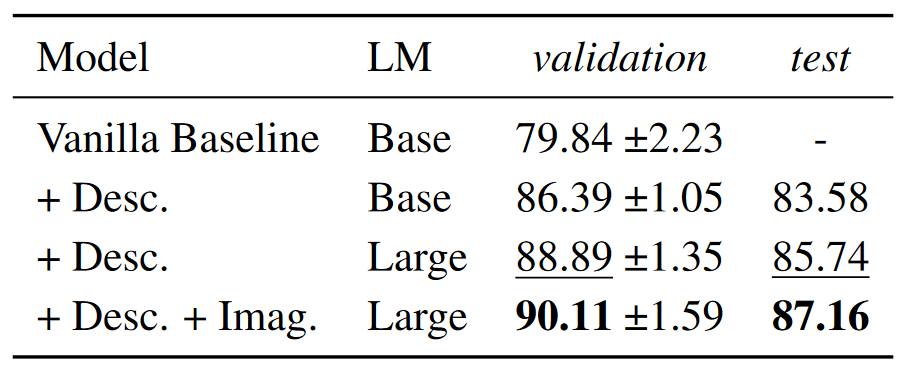 Detecting Euphemisms with Literal Descriptions and Visual ImageryIlker Kesen , Aykut Erdem , Erkut Erdem , and Iacer CalixtoIn Proceedings of the 3rd Workshop on Figurative Language Processing (FLP) , Dec 2022
Detecting Euphemisms with Literal Descriptions and Visual ImageryIlker Kesen , Aykut Erdem , Erkut Erdem , and Iacer CalixtoIn Proceedings of the 3rd Workshop on Figurative Language Processing (FLP) , Dec 2022This paper describes our two-stage system for the Euphemism Detection shared task hosted by the 3rd Workshop on Figurative Language Processing in conjunction with EMNLP 2022. Euphemisms tone down expressions about sensitive or unpleasant issues like addiction and death. The ambiguous nature of euphemistic words or expressions makes it challenging to detect their actual meaning within a context. In the first stage, we seek to mitigate this ambiguity by incorporating literal descriptions into input text prompts to our baseline model. It turns out that this kind of direct supervision yields remarkable performance improvement. In the second stage, we integrate visual supervision into our system using visual imageries, two sets of images generated by a text-to-image model by taking terms and descriptions as input. Our experiments demonstrate that visual supervision also gives a statistically significant performance boost. Our system achieved the second place with an F1 score of 87.2%, only about 0.9% worse than the best submission.
@inproceedings{kesen-etal-2022-detecting, title = {Detecting Euphemisms with Literal Descriptions and Visual Imagery}, author = {Kesen, Ilker and Erdem, Aykut and Erdem, Erkut and Calixto, Iacer}, booktitle = {Proceedings of the 3rd Workshop on Figurative Language Processing (FLP)}, month = dec, year = {2022}, address = {Abu Dhabi, United Arab Emirates (Hybrid)}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.flp-1.9}, doi = {10.18653/v1/2022.flp-1.9}, pages = {61--67}, } -
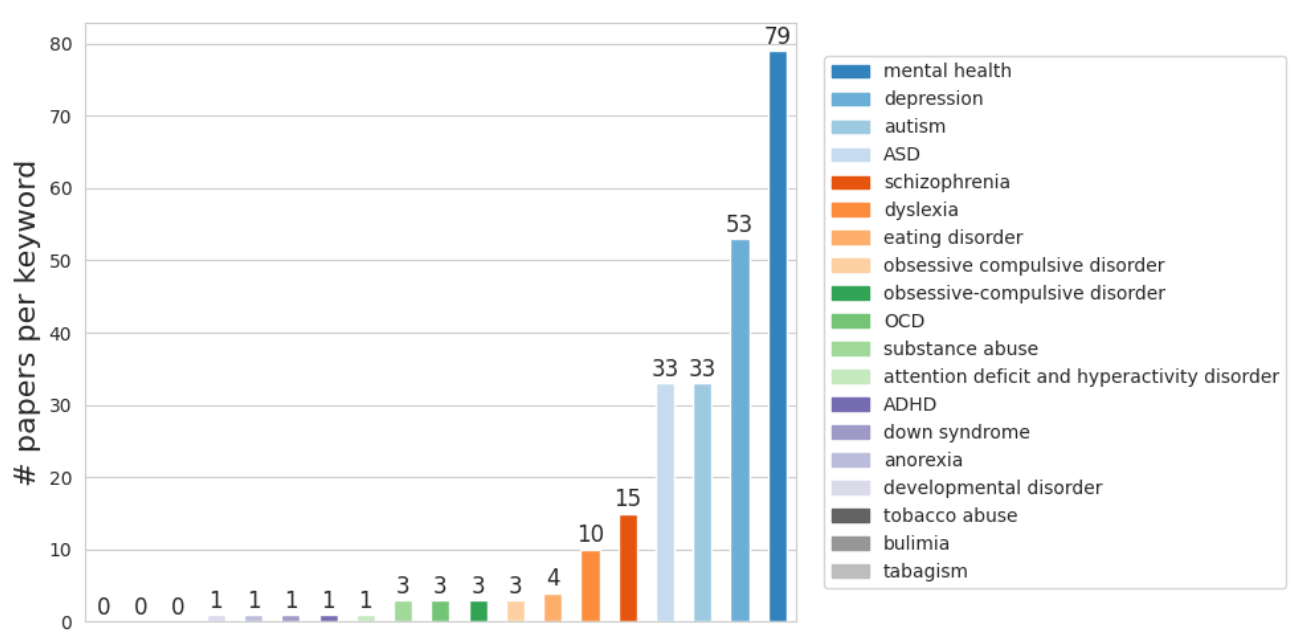 Natural language processing for mental disorders: an overviewIacer Calixto , Viktoriya Yaneva , and Raphael CardosoIn Natural Language Processing in Healthcare: A Special Focus on Low Resource Languages , Dec 2022
Natural language processing for mental disorders: an overviewIacer Calixto , Viktoriya Yaneva , and Raphael CardosoIn Natural Language Processing in Healthcare: A Special Focus on Low Resource Languages , Dec 2022In recent years, there has been a surge in interest in using natural language processing (NLP) applications for clinical psychology and psychiatry. Despite the increased societal, economic, and academic interest, there has been no systematic critical analysis of the recent progress in NLP applications for mental disorders, or of the resources available for training and evaluating such systems. This chapter addresses this gap through two main contributions. First, it provides an overview of the NLP literature related to mental disorders, with a focus on autism, dyslexia, schizophrenia, depression and mental health in general. We discuss the strengths and shortcomings of current methodologies, specifically focusing on the challenges in obtaining large volumes of high-quality domain-specific data both for English and for lower-resource languages. We also provide a list of datasets publicly available for researchers who would like to develop NLP methods for specific mental disorders, categorized according to relevant criteria such as data source, language, annotation, and size. Our second contribution is a discussion on how to support the application of these methods to various languages and social contexts. This includes recommendations on conducting robust and ethical experiments from a machine learning perspective, and a discussion on how techniques such as cross-lingual transfer learning could be applied within this area.
@incollection{2436/624261, author = {Calixto, Iacer and Yaneva, Viktoriya and Cardoso, Raphael}, title = {Natural language processing for mental disorders: an overview}, publisher = {CRC Press}, editor = {}, booktitle = {Natural Language Processing in Healthcare: A Special Focus on Low Resource Languages}, year = {2022}, pages = {37-59}, isbn = {9780367685393}, doi = {https://doi.org/10.1201/9781003138013}, url = {http://hdl.handle.net/2436/624261}, } -
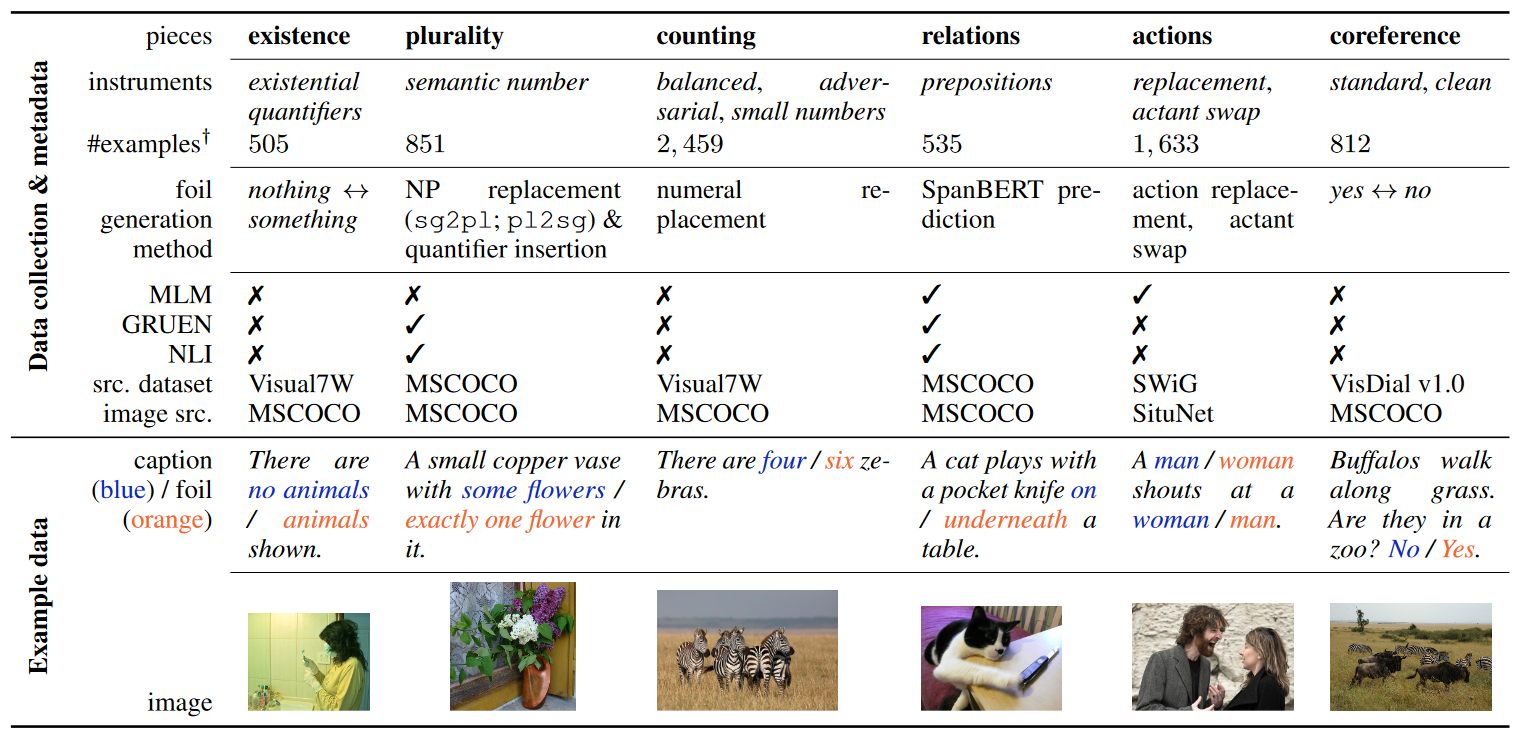 VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic PhenomenaLetitia Parcalabescu , Michele Cafagna , Lilitta Muradjan , Anette Frank , Iacer Calixto , and Albert GattIn Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , May 2022
VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic PhenomenaLetitia Parcalabescu , Michele Cafagna , Lilitta Muradjan , Anette Frank , Iacer Calixto , and Albert GattIn Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , May 2022We propose VALSE (Vision And Language Structured Evaluation), a novel benchmark designed for testing general-purpose pretrained vision and language (V&L) models for their visio-linguistic grounding capabilities on specific linguistic phenomena. VALSE offers a suite of six tests covering various linguistic constructs. Solving these requires models to ground linguistic phenomena in the visual modality, allowing more fine-grained evaluations than hitherto possible. We build VALSE using methods that support the construction of valid foils, and report results from evaluating five widely-used V&L models. Our experiments suggest that current models have considerable difficulty addressing most phenomena. Hence, we expect VALSE to serve as an important benchmark to measure future progress of pretrained V&L models from a linguistic perspective, complementing the canonical task-centred V&L evaluations.
@inproceedings{parcalabescu-etal-2022-valse, title = {{VALSE}: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena}, author = {Parcalabescu, Letitia and Cafagna, Michele and Muradjan, Lilitta and Frank, Anette and Calixto, Iacer and Gatt, Albert}, booktitle = {Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = may, year = {2022}, address = {Dublin, Ireland}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.acl-long.567}, doi = {10.18653/v1/2022.acl-long.567}, pages = {8253--8280}, }




